Statistisk sentralbyrå (SSB) driver med innsamling og analyse av data om mange ulike norske parametere.
Hvordan importere data fra SSB til R
For å importere data fra SSB til R trenger man en pakke som heter PxWebApiData . Dokumentasjonen på denne pakken kan være litt komplisert, og dermed lager vi dette blogg innlegget for å gjøre det enkelt for deg og forstå slik at du slipper å kaste bort verdifull tid! La oss begynne! Nederst i blogg innlegget ligger det en lenke til .R filen slik at du selv kan prøve deg frem.
Steg 1: Installere og laste inn PxWebApiData
Følgende kode vil installere og laste inn pakken som trengs videre. Jeg laster også inn tidyverse da denne er nyttig for senere når vi skal visualisere funnene fra SSB:
if (!require("PxWebApiData")) install.packages("PxWebApiData") # Install package PxWebApiData if not found.
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
Steg 2: Finn data
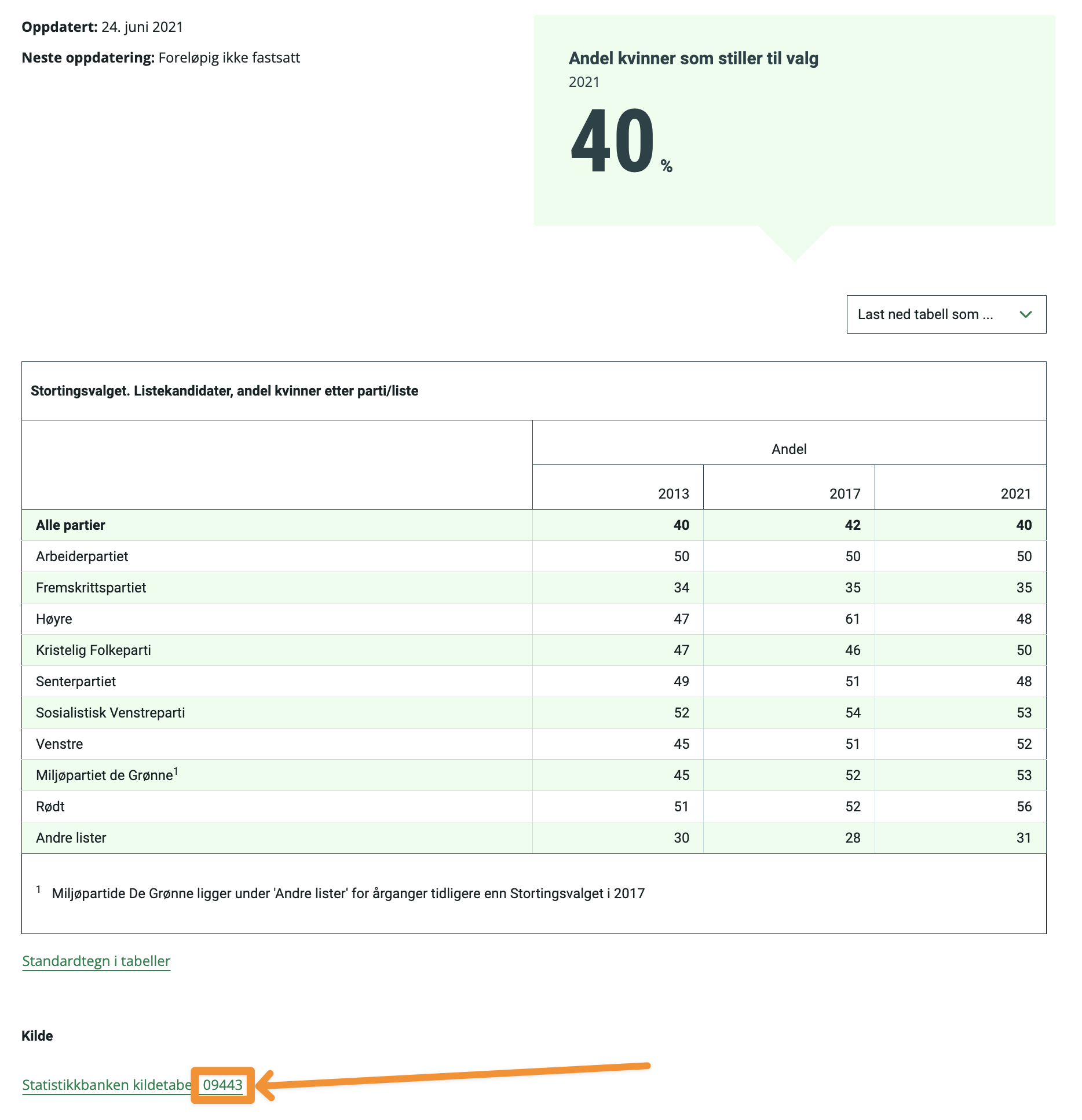
Når du er inne i SSB kan du lete etter en tabell som du ønsker å bruke for å gjøre dine analyser. Se for eksempel på denne tabellen: SSB - Stortingsvalget listekandidater. Dersom du scroller ned litt vil du se at denne tabellen har en kilde, det tallet tar du vare på. Se bilde nedenfor:
Kildenummer til en tabell
Steg 3: Importer tabellen
Nå som du har det tallet på tabellen du ønsker å analysere, må vi få dette inn i R . For å få dette til må du skrive følgende kode, der du bytter ut "09443" med navnet på din kode.
Da vil man få opp alle kategoriene som man kan filtrere på senere, for eksempel ved å indeksere kjønn listen ser vi at det er to muligheter: “1” og “2”. Altså, kjønn 1 og kjønn 2. Vi må nå skjønne hva disse egentlig betyr, du kan da skrive:
values[[3]] # Denne koden vil vise både verdi og "valueTexts" som er forklaringen på hva variabelen betyr.
Next up, datavask. Som du ser i koden er ikke koden direkte leselig enda, vi ønsker å gjøre tabellen om til et dataset. Nedenfor ser du en måte å gjøre dette, da også med filtrering av variabler:
my_data <-ApiData("https://data.ssb.no/api/v0/no/table/09443",Tid =c("2005", "2021"), # Velger 2005 og 2021 som årstall.Region ="0", # Velger alle regionerPolitParti =c("Alle partier"), # Velger alle partierKjonn =c("1", "2") # Velger alle kjønn. )my_data <- my_data[[1]]
Den siste linjen i koden forteller R at vi ønsker å bare ha med indeks 1 (verdiene som “1” og “2” fra kjønn). Dermed forsvinner valueTexts og du vil se i Enviornment at tabellen går fra en liste (list of 2) til en data frame ( 4 obs. of 6 variables). Dermed er vi klare til å analysere datasettet vårt.
Steg 5: Analysere og visualisering
Dersom man ønsker å få en liten oversikt over datasettet kan man gjøre slik som normalt, for å se de første observasjonene kan vi gjøre:
head(my_data) # Vi får her fire observasjoner, fordi det er alle observasjonene vårt dataset har.
region politisk parti kjønn statistikkvariabel fireårlig value
1 Hele landet Alle partier Menn Listekandidater 2005 2313
2 Hele landet Alle partier Menn Listekandidater 2021 3116
3 Hele landet Alle partier Kvinner Listekandidater 2005 1501
4 Hele landet Alle partier Kvinner Listekandidater 2021 2058
Man kan i tillegg bruke funksjonen comment() fra PxWebApiData pakken for å se label av tabellen vi hentet ut. Dette er nyttig for å kunne huske hva tabellen egentlig handlet om, samtidig får man se kilden (SSB) og når den sist var oppdatert. I eksempelet er den sist oppdatert 2021-06-28T06:00:00Z , altså, 28. juni 2021 kl. 06:00.
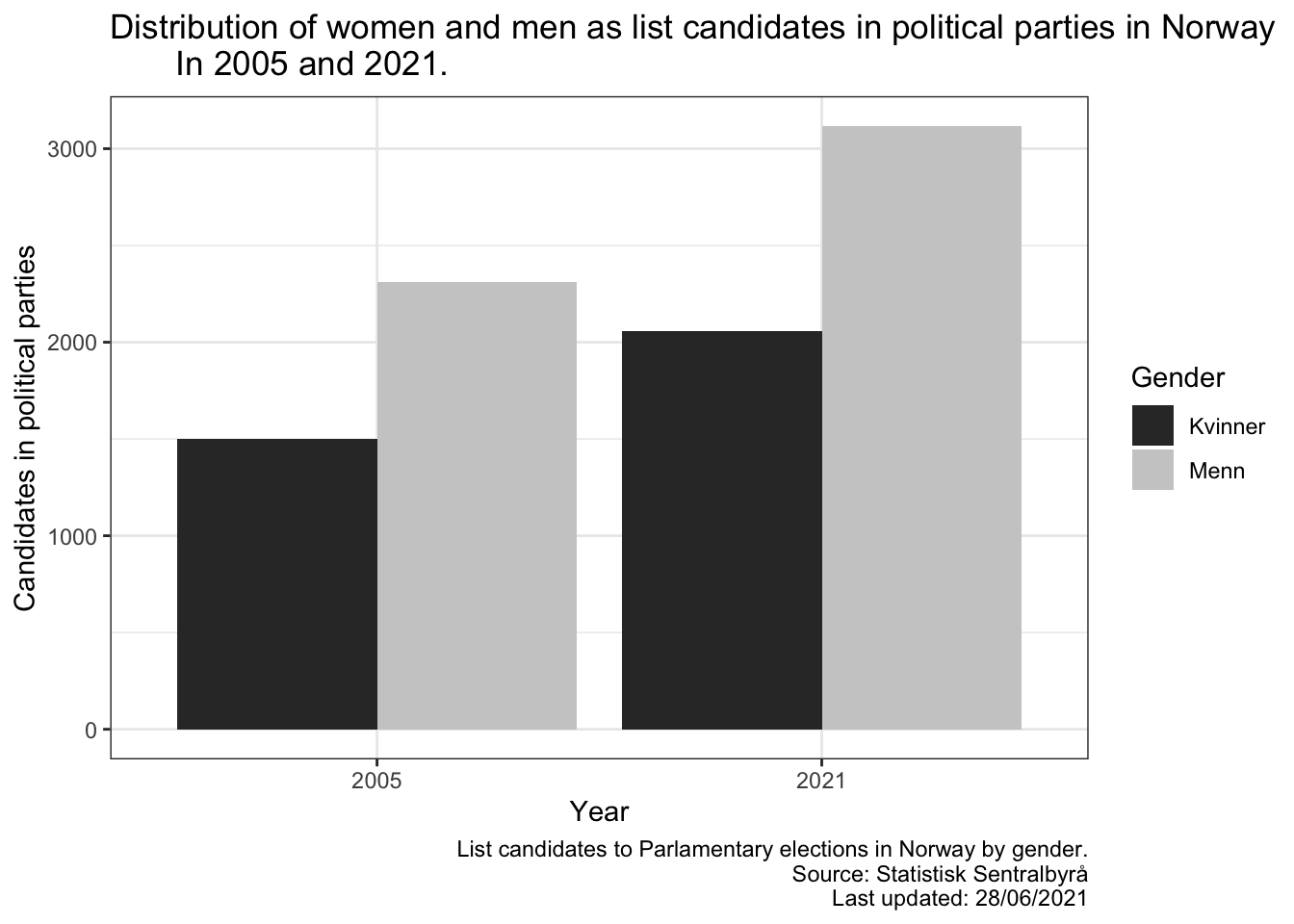
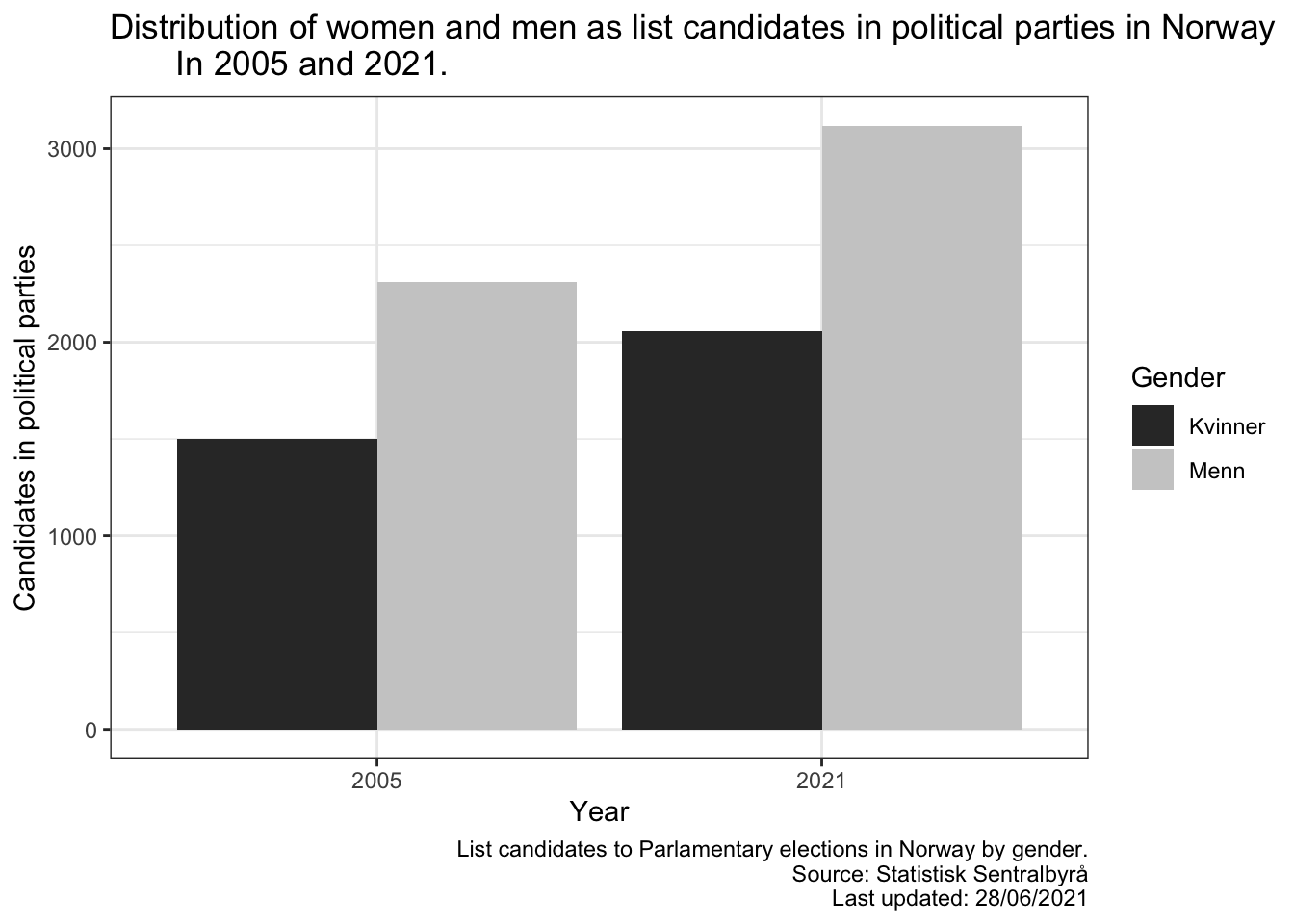
Til slutt, så skal vi visualisere tabellen vi har hentet ut fra SSB. Dette gjøres likt som du er vant med fra ESS, CPDS eller lignende datasett. Her er et eksempel på et stolpediagram som ser på forskjellen mellom listekandidater i 2005 og 2021 fordelt på kjønn:
my_data %>%ggplot(aes(x = fireårlig,y = value,fill = kjønn)) +labs(title ="Distribution of women and men as list candidates in political parties in Norway In 2005 and 2021.",x ="Year",y ="Candidates in political parties",fill ="Gender",caption ="List candidates to Parlamentary elections in Norway by gender. Source: Statistisk Sentralbyrå Last updated: 28/06/2021") +theme_bw() +geom_bar(stat ="identity",position ="dodge") +scale_fill_grey()
Oppsummering
I dette blogg innlegget lærte du hvordan man importerer tabeller fra SSB til R. Takk for at du leste dette blogg innlegget og jeg håper du ble litt klokere! Har du noen spørsmål? Gjerne ta kontakt med oss på codinghjornet@gmail.com!
Ønsker du og prøve deg frem med skriptet i sin helhet i RStudio? Kopier hele denne koden inn i RStudio:
if (!require("PxWebApiData")) install.packages("PxWebApiData")library(PxWebApiData)library(tidyverse)variables <-ApiData("https://data.ssb.no/api/v0/no/table/09443",returnMetaFrames =TRUE)names(variables)values <-ApiData("https://data.ssb.no/api/v0/no/table/09443",returnMetaFrames =TRUE)values[[1]]$values # Regionvalues[[2]]$values # Politisk partivalues[[3]]$values # Kjønnvalues[[4]]$values # Kandidatervalues[[5]]$values # Tidmy_data <-ApiData("https://data.ssb.no/api/v0/no/table/09443",Tid =c("2005", "2021"),Region ="0", PolitParti =c("Alle partier"),Kjonn =c("1", "2") )my_data <- my_data[[1]]head(my_data)comment(my_data)my_data %>%ggplot(aes(x = fireårlig,y = value,fill = kjønn)) +labs(title ="Distribution of women and men as list candidates in political parties in Norway In 2005 and 2021.",x ="Year",y ="Candidates in political parties",fill ="Gender",caption ="List candidates to Parlamentary elections in Norway by gender. Source: Statistisk Sentralbyrå Last updated: 28/06/2021") +theme_bw() +geom_bar(stat ="identity",position ="dodge") +scale_fill_grey()